2026
Speculative Decoding for Multimodal Models: A Survey
Yifan Zhang, Yuren Wang, Yunta Hsieh, Xin Wang, Ping Zhang, Ziyi Yang, Jianing Ma, Zesen Zhao, Boyuan Zheng, Hei Ting (Una) Chan, Jiarui Li, Xueshen Liu, Kunxiao Gao, Yanheng Shang, Ruoyan Zhang, Ruiyao Liu, Jingxuan Zhang, Junchen Li, Zhongwei Wan, Ziheng Zhang, Jing Xiong, Shatong Zhu, Hangrui Cao, Hui Shen
Preprints 2026 Preprint
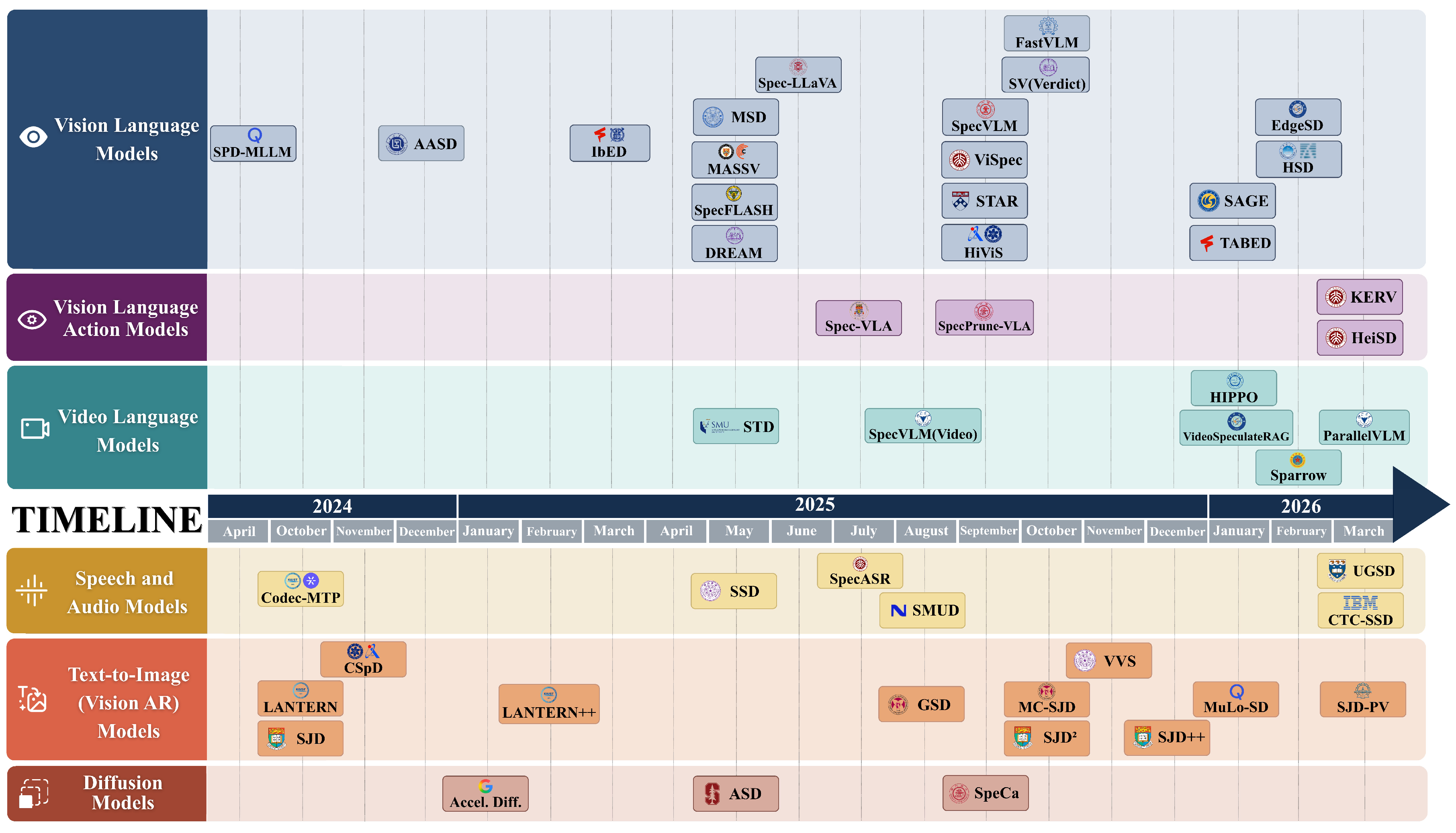
Speculative decoding has emerged as a promising paradigm for accelerating inference without degrading output quality, but most existing surveys focus on text-only large language models. This survey provides a systematic review of speculative decoding methods for multimodal models, covering vision-language, vision-language-action, video-language, speech, text-to-image, and diffusion models. It organizes the literature around draft generation, verification and acceptance, and inference framework support, identifying recurring cross-modal patterns such as token compression, KV cache optimization, target-informed transfer, drafter-target alignment, relaxed acceptance, and verify-to-draft feedback.
Speculative Decoding for Multimodal Models: A Survey
Yifan Zhang, Yuren Wang, Yunta Hsieh, Xin Wang, Ping Zhang, Ziyi Yang, Jianing Ma, Zesen Zhao, Boyuan Zheng, Hei Ting (Una) Chan, Jiarui Li, Xueshen Liu, Kunxiao Gao, Yanheng Shang, Ruoyan Zhang, Ruiyao Liu, Jingxuan Zhang, Junchen Li, Zhongwei Wan, Ziheng Zhang, Jing Xiong, Shatong Zhu, Hangrui Cao, Hui Shen
Preprints 2026 Preprint
Speculative decoding has emerged as a promising paradigm for accelerating inference without degrading output quality, but most existing surveys focus on text-only large language models. This survey provides a systematic review of speculative decoding methods for multimodal models, covering vision-language, vision-language-action, video-language, speech, text-to-image, and diffusion models. It organizes the literature around draft generation, verification and acceptance, and inference framework support, identifying recurring cross-modal patterns such as token compression, KV cache optimization, target-informed transfer, drafter-target alignment, relaxed acceptance, and verify-to-draft feedback.
Potentially Optimal Joint Actions Recognition for Cooperative Multi-Agent Reinforcement Learning
Chang Huang*, Shatong Zhu*, Junqiao Zhao, Hongtu Zhou, Hai Zhang, Di Zhang, Chen Ye, Ziqiao Wang, Guang Chen (* equal contribution)
International Conference on Learning Representations (ICLR) 2026 ICLR 2026 Poster
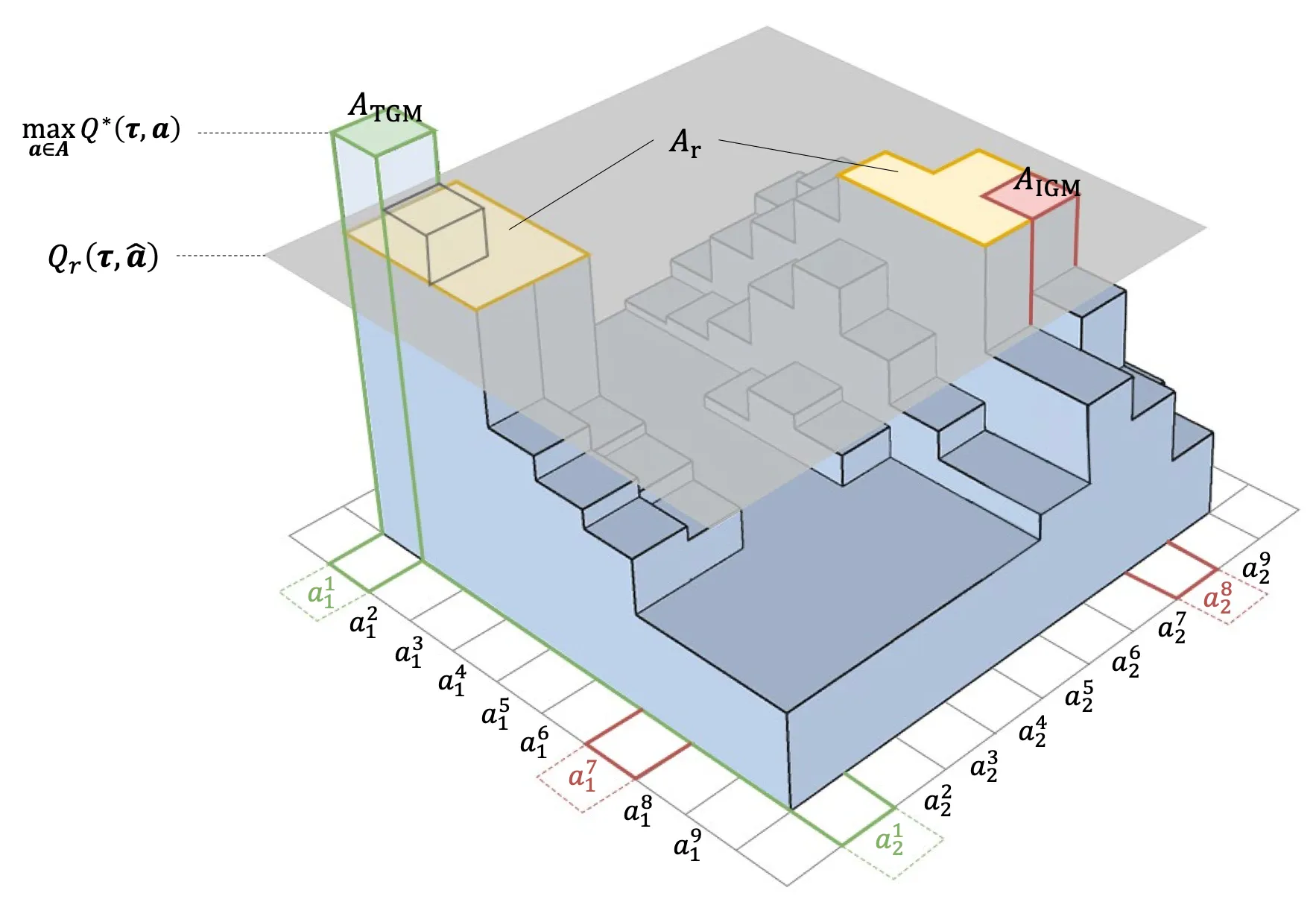
Value function factorization is widely used in cooperative multi-agent reinforcement learning, but monotonicity constraints can limit expressiveness and hinder optimal policy learning. This work proposes Potentially Optimal Joint Actions Weighting (POW), an architecture-agnostic method that iteratively identifies potentially optimal joint actions and assigns them higher training weights. The approach provides a theoretical guarantee for recovering the optimal joint policy and improves stability and performance across matrix games, difficulty-enhanced predator-prey, SMAC, SMACv2, and highway-env intersection scenarios.
Potentially Optimal Joint Actions Recognition for Cooperative Multi-Agent Reinforcement Learning
Chang Huang*, Shatong Zhu*, Junqiao Zhao, Hongtu Zhou, Hai Zhang, Di Zhang, Chen Ye, Ziqiao Wang, Guang Chen (* equal contribution)
International Conference on Learning Representations (ICLR) 2026 ICLR 2026 Poster
Value function factorization is widely used in cooperative multi-agent reinforcement learning, but monotonicity constraints can limit expressiveness and hinder optimal policy learning. This work proposes Potentially Optimal Joint Actions Weighting (POW), an architecture-agnostic method that iteratively identifies potentially optimal joint actions and assigns them higher training weights. The approach provides a theoretical guarantee for recovering the optimal joint policy and improves stability and performance across matrix games, difficulty-enhanced predator-prey, SMAC, SMACv2, and highway-env intersection scenarios.
2024
Coordinated Optimization and Configuration Optimization of Wind, Photovoltaics and Energy Storage based on Particle Swarm Optimization Algorithm
Shatong Zhu*, Yifan Zhang* (* equal contribution)
International Conference on Big Data, Artificial Intelligence and Software Engineering (ICBASE) 2024 IEEE
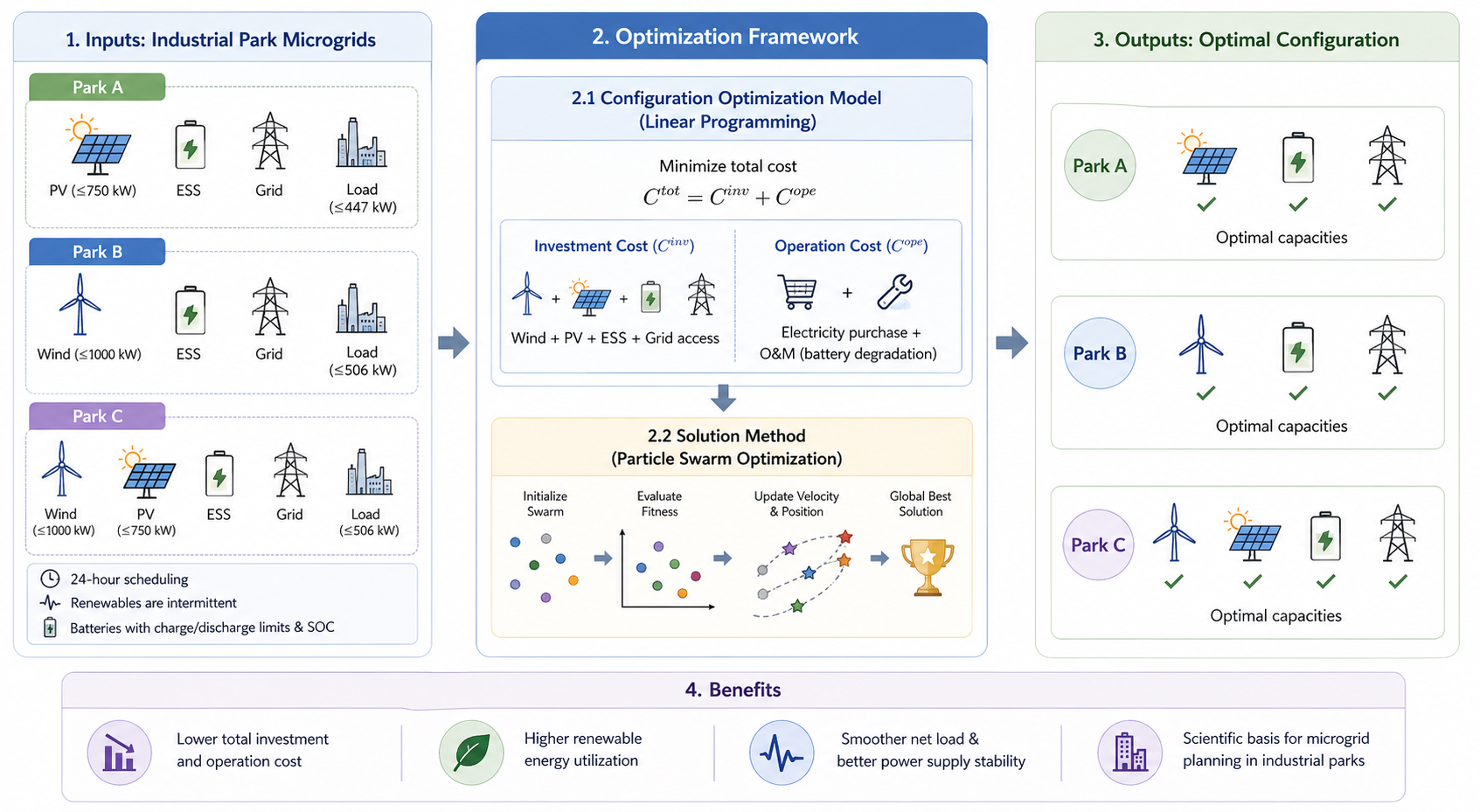
This work studies coordinated optimization and configuration optimization for wind, photovoltaic, and energy storage systems in industrial park scenarios. We formulate the system as a mathematical optimization problem and apply particle swarm optimization to search for cost-effective configurations that coordinate generation, consumption, and storage. The method aims to reduce electricity cost and generation waste while improving the reliability and stability of the power supply.
Coordinated Optimization and Configuration Optimization of Wind, Photovoltaics and Energy Storage based on Particle Swarm Optimization Algorithm
Shatong Zhu*, Yifan Zhang* (* equal contribution)
International Conference on Big Data, Artificial Intelligence and Software Engineering (ICBASE) 2024 IEEE
This work studies coordinated optimization and configuration optimization for wind, photovoltaic, and energy storage systems in industrial park scenarios. We formulate the system as a mathematical optimization problem and apply particle swarm optimization to search for cost-effective configurations that coordinate generation, consumption, and storage. The method aims to reduce electricity cost and generation waste while improving the reliability and stability of the power supply.

Towards an Information Theoretic Framework of Context-Based Offline Meta-Reinforcement Learning
Lanqing Li*, Hai Zhang*, Xinyu Zhang, Shatong Zhu, Yang Yu, Junqiao Zhao, Pheng-Ann Heng (* equal contribution)
Advances in Neural Information Processing Systems (NeurIPS) 2024 NeurIPS 2024 Spotlight
As a marriage between offline reinforcement learning and meta-reinforcement learning, context-based offline meta-RL aims to learn a universal policy conditioned on effective task representations. This work shows that several mainstream COMRL methods can be understood as optimizing the same mutual-information objective between the task variable and its latent representation via different approximate bounds. The framework leads to supervised and self-supervised implementations that generalize across RL benchmarks, context shift scenarios, data qualities, and deep learning architectures, providing an information-theoretic foundation for task representation learning in offline meta-RL.
Towards an Information Theoretic Framework of Context-Based Offline Meta-Reinforcement Learning
Lanqing Li*, Hai Zhang*, Xinyu Zhang, Shatong Zhu, Yang Yu, Junqiao Zhao, Pheng-Ann Heng (* equal contribution)
Advances in Neural Information Processing Systems (NeurIPS) 2024 NeurIPS 2024 Spotlight
As a marriage between offline reinforcement learning and meta-reinforcement learning, context-based offline meta-RL aims to learn a universal policy conditioned on effective task representations. This work shows that several mainstream COMRL methods can be understood as optimizing the same mutual-information objective between the task variable and its latent representation via different approximate bounds. The framework leads to supervised and self-supervised implementations that generalize across RL benchmarks, context shift scenarios, data qualities, and deep learning architectures, providing an information-theoretic foundation for task representation learning in offline meta-RL.