
 M.S. Student in Electrical Engineering @ Stanford University
M.S. Student in Electrical Engineering @ Stanford UniversityI am a Master's student in Electrical Engineering at Stanford University, focusing on software and computer systems, machine learning, and optimization. I am broadly interested in agentic AI, AI infrastructure, and robust learning systems that connect theory with deployable software.
My research experience spans cooperative multi-agent reinforcement learning, offline meta-reinforcement learning, and large language model applications. Before Stanford, I earned a B.Eng. in Data Science from Tongji University, where I worked on mathematical modeling, data mining, and optimization-driven AI systems.
I have also built applied AI systems in industry, including RAG-powered search, LLM application workflows, and agentic BI systems for Text-to-SQL and structured analytics.
Education
-
Stanford UniversityDepartment of Electrical Engineering
-
 Tongji UniversitySchool of Computer Science
Tongji UniversitySchool of Computer Science
Honors & Awards
-
ICLR 2026 paper acceptance in cooperative multi-agent reinforcement learning2026
-
NeurIPS 2024 Spotlight paper on context-based offline meta-reinforcement learning2024
-
National Scholarship, Tongji University (top 0.2%), second-time laureate2024
-
National First Prize, RoboCup China Open2024
-
National First Prize, Information Security and Countermeasures Competition2024
-
Outstanding Graduate, Tongji University2025
Experience
Incoming role focused on AI/ML software systems and infrastructure.
- Preparing to work on production-oriented AI/ML systems at the intersection of software engineering and intelligent infrastructure.

Built agent-powered BI workflows for Text-to-SQL and structured analytics.
- Built a conversational intake workflow that generated structured JSON for downstream BI analytics and automation.
- Upgraded the LangChain pipeline with RAG, a FastAPI retrieval API, FAISS vector search, and HTTP connection pooling for more stable serving.
- Led a 4-intern team with code reviews and documentation standards to deliver the system on schedule.

Contributed to early LLM application systems including MeetAsk, RAG search, and multi-agent workflows.
- Implemented RAG modules for an enterprise Q&A platform with hybrid retrieval over vector and keyword search systems.
- Optimized prompt and multi-agent workflows for topic identification, keyword extraction, and structured response quality.
- Built review-insight and content-understanding pipelines using topic modeling and LLM-assisted summarization.
News
Selected Publications (view all)
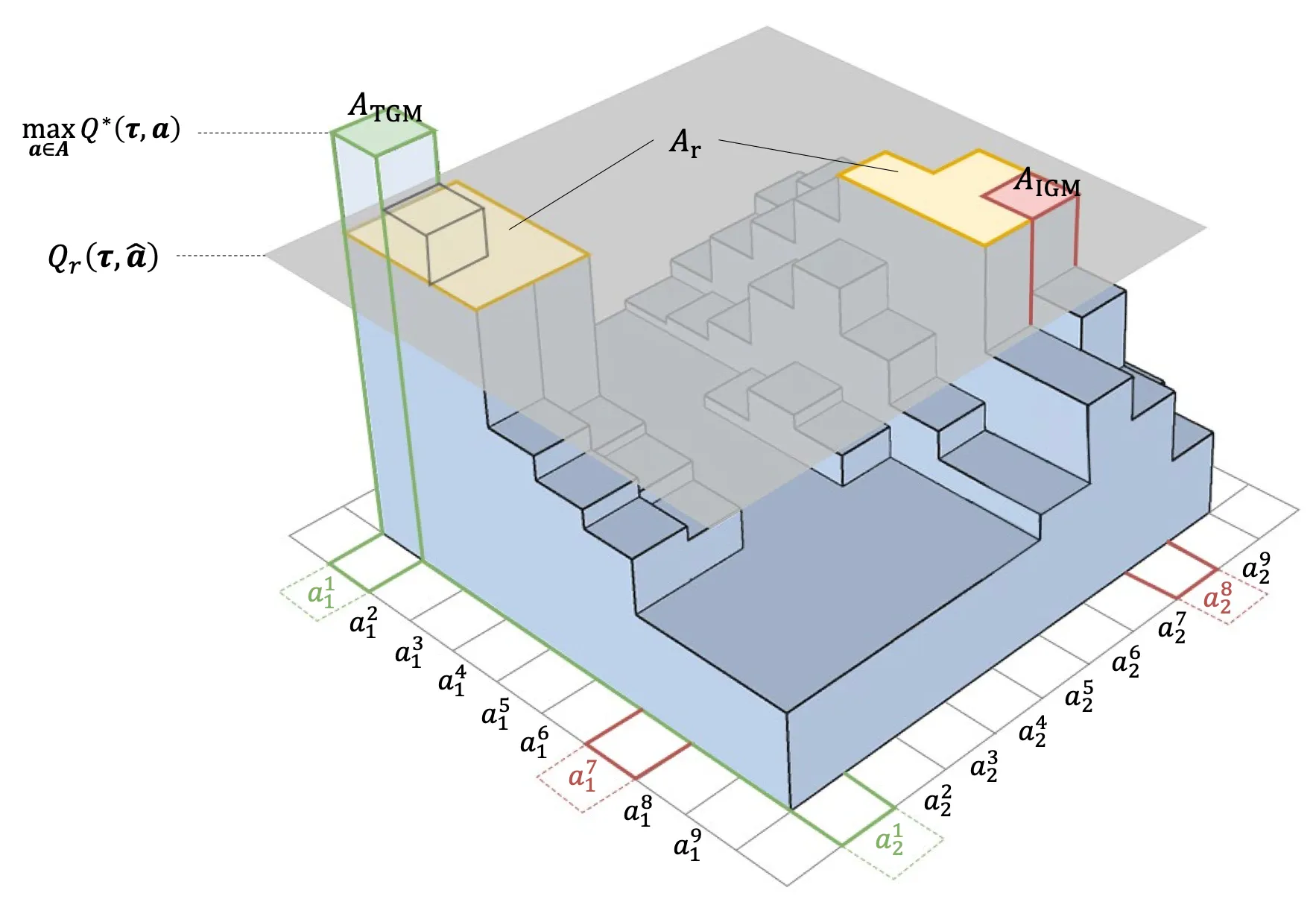
Potentially Optimal Joint Actions Recognition for Cooperative Multi-Agent Reinforcement Learning
Chang Huang*, Shatong Zhu*, Junqiao Zhao, Hongtu Zhou, Hai Zhang, Di Zhang, Chen Ye, Ziqiao Wang, Guang Chen (* equal contribution)
International Conference on Learning Representations (ICLR) 2026 ICLR 2026 Poster
Value function factorization is widely used in cooperative multi-agent reinforcement learning, but monotonicity constraints can limit expressiveness and hinder optimal policy learning. This work proposes Potentially Optimal Joint Actions Weighting (POW), an architecture-agnostic method that iteratively identifies potentially optimal joint actions and assigns them higher training weights. The approach provides a theoretical guarantee for recovering the optimal joint policy and improves stability and performance across matrix games, difficulty-enhanced predator-prey, SMAC, SMACv2, and highway-env intersection scenarios.
Potentially Optimal Joint Actions Recognition for Cooperative Multi-Agent Reinforcement Learning
Chang Huang*, Shatong Zhu*, Junqiao Zhao, Hongtu Zhou, Hai Zhang, Di Zhang, Chen Ye, Ziqiao Wang, Guang Chen (* equal contribution)
International Conference on Learning Representations (ICLR) 2026 ICLR 2026 Poster
Value function factorization is widely used in cooperative multi-agent reinforcement learning, but monotonicity constraints can limit expressiveness and hinder optimal policy learning. This work proposes Potentially Optimal Joint Actions Weighting (POW), an architecture-agnostic method that iteratively identifies potentially optimal joint actions and assigns them higher training weights. The approach provides a theoretical guarantee for recovering the optimal joint policy and improves stability and performance across matrix games, difficulty-enhanced predator-prey, SMAC, SMACv2, and highway-env intersection scenarios.

Towards an Information Theoretic Framework of Context-Based Offline Meta-Reinforcement Learning
Lanqing Li*, Hai Zhang*, Xinyu Zhang, Shatong Zhu, Yang Yu, Junqiao Zhao, Pheng-Ann Heng (* equal contribution)
Advances in Neural Information Processing Systems (NeurIPS) 2024 NeurIPS 2024 Spotlight
As a marriage between offline reinforcement learning and meta-reinforcement learning, context-based offline meta-RL aims to learn a universal policy conditioned on effective task representations. This work shows that several mainstream COMRL methods can be understood as optimizing the same mutual-information objective between the task variable and its latent representation via different approximate bounds. The framework leads to supervised and self-supervised implementations that generalize across RL benchmarks, context shift scenarios, data qualities, and deep learning architectures, providing an information-theoretic foundation for task representation learning in offline meta-RL.
Towards an Information Theoretic Framework of Context-Based Offline Meta-Reinforcement Learning
Lanqing Li*, Hai Zhang*, Xinyu Zhang, Shatong Zhu, Yang Yu, Junqiao Zhao, Pheng-Ann Heng (* equal contribution)
Advances in Neural Information Processing Systems (NeurIPS) 2024 NeurIPS 2024 Spotlight
As a marriage between offline reinforcement learning and meta-reinforcement learning, context-based offline meta-RL aims to learn a universal policy conditioned on effective task representations. This work shows that several mainstream COMRL methods can be understood as optimizing the same mutual-information objective between the task variable and its latent representation via different approximate bounds. The framework leads to supervised and self-supervised implementations that generalize across RL benchmarks, context shift scenarios, data qualities, and deep learning architectures, providing an information-theoretic foundation for task representation learning in offline meta-RL.